
Web 3
Z.ai Launches GLM-4.5V: Open-source Vision-Language Model Sets New Bar for Multimodal Reasoning
Credit : web3wire.org

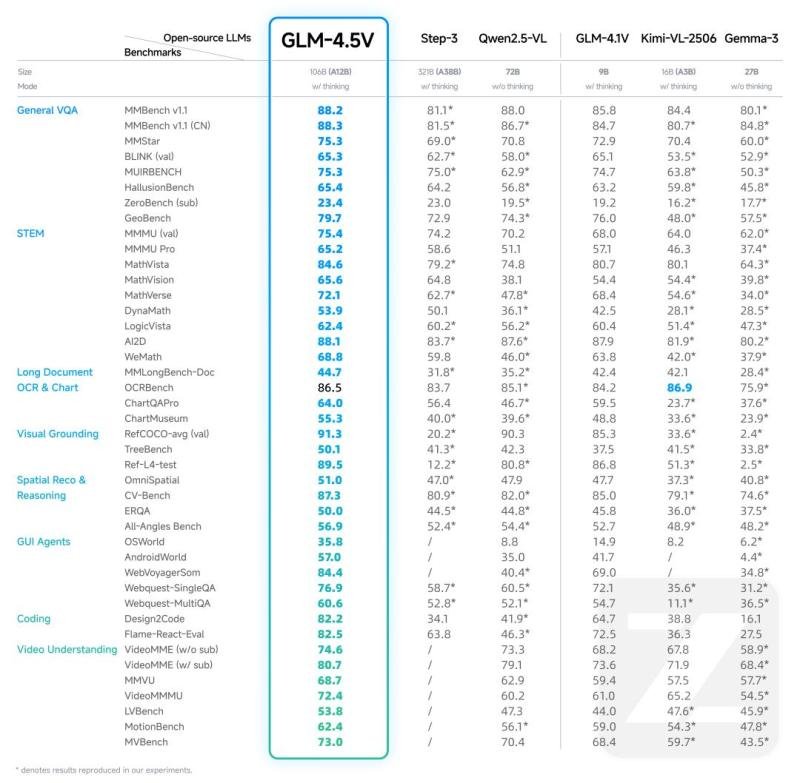
Z.AI (previously Zchipu) introduced GLM-4.5V right this moment, designed an open-source imaginative and prescient language mannequin for sturdy multimodal reasoning about photographs, video, lengthy paperwork, graphs and GUI screens.
Multimodal reasoning is mostly seen as a key street to Agi. GLM-4.5V promotes this agenda with a 100B class structure (106b whole parameters, 12B lively) that mixes excessive accuracy with sensible latency and implementation prices. The discharge follows GLM-4.1V-9B-Thinging, which hit #1 on hugging face trending and 130,000 downloads and scales which have surpassed a recipe for enterprise workload, whereas developer Ergonomics turns into ergonomics for and within the center. The mannequin is accessible through a number of channels, together with a cuddly face [http://huggingface.co/zai-org/GLM-4.5V]Github [http://github.com/zai-org/GLM-V]Z.AI API platform [http://docs.z.ai/guides/vlm/glm-4.5v]and z.ai chat [http://chat.z.ai]Guarantee broad entry to builders.
Open-source Sota
Constructed on the brand new GLM-4.5-Air textual content base and the enlargement of the GLM-4.1V-thinking line, GLM-4.5V SOTA efficiency below comparable open-source VLMs of comparable measurement over 41 public multimodal evaluations. Along with leaderboards, the mannequin is designed for usability and reliability in observe on noisy, excessive decision and excessive facet ratio inputs.
The result’s all-scenario visible reasoning in sensible pipelines: Picture reasoning (scene idea, multi-image evaluation, localization), video perception (shot segmentation and occasion recognition), GUI duties (display screen studying, icon detection, desktop assist), advanced graphic and evaluation of the long-of-turacticness of the long-dysis of the long-dysydies of the long-of-turactive-oriented one-orpetative Areas (correct spatial location of visible components).
Picture: https://www.globalnewsles.com/uploads/2025/08/1ca45A47819aAF6A11E702A896EE2BC.JPG
Predominant potentialities
Visible grounding and localization
GLM-4.5V identifies and locates goal objects exactly on the premise of pure language prompts and returns limitation coordinates. This makes high-quality purposes attainable, corresponding to security and high quality inspection or evaluation of the air/exterior sensing. Compared with typical detectors, the mannequin makes use of broader world information and a stronger semantic reasoning to observe extra advanced localization directions.
Customers can change to the visible positioning mode, a picture and a brief immediate add and get the field and the reasoning again. For instance, ask: “Level out non-right objects to this picture.” GLM-4.5V Causes about plausibility and supplies, then marks the Insect-like sprinkler robotic (the merchandise marked within the demo within the demo) as a non-real, so {that a} tightly restricted field returns a reliability rating and a brief rationalization.
Design-to-code of screenshots and interplay movies
The mannequin analyzes web page screenshots and even interplay movies to infer hierarchy, structure guidelines, types and intention after which radiates loyal, Runnable HTML/CSS/Javascript. Along with aspect detection, it reconstructs the underlying logic and helps processing requests on the regional stage, making an iterative loop between visible enter and production-ready code attainable.
Open-World Exact Reasoning
GLM-4.5V can deduce background context from delicate visible indicators with out an exterior search. Given a panorama or avenue photograph, the reasoning of vegetation, local weather tracks, signage and architectural types can estimate the capturing location and estimated coordinates.
For instance, with the assistance of a traditional scene of Earlier than Dawn -“based mostly on structure and streets within the background, are you able to establish the precise location in Vienna the place this scene was filmed?” -The mannequin parses facade particulars, avenue furnishings and lay -out indicators to find the precise place in Vienna and to return coordinates and a Landmarkknam. (See demo: https://chat.z.ai/s/39233f25-8CE5-4488-9642-E07e7c638ef6).
Picture: htts
Along with just a few photographs, GLM-4.5V’s Open-World Reasoning scales in aggressive establishments: in a worldwide ‘Geo-Recreation’, it defeated 99% of human gamers inside 16 hours and climbed clearly proof of strong Actual-World efficiency inside seven days.
Advanced doc and graph idea
The mannequin reads paperwork visually pages, figures, tables and graphs that provide the pinnacle than on Brosse OCR pipelines. This end-to-end strategy retains the construction and structure, which improves the accuracy for abstract, translation, info extraction and commentary in lengthy, reviews with blended media.
GUI agent basis
Constructed-up display screen comprehension Let GLM-4.5V interfaces learn, discover icons and controls and mix the present visible situation with person directions to plan actions. Together with agent, Runtimes helps end-to-end desktop automation and complicated GUI-agent duties, which provide a dependable visible spine for agent methods.
Constructed for reasoning, designed to be used
GLM-4.5V is constructed on the brand new GLM-4.5-Air textual content base and makes use of a contemporary VLM pipeline vision-encoder, MLP adapter and LLM-Dododal-with 64k multimodal context, native picture and video inputs and improved spatial-temporaling and excessive uphing capability with stability processed.
The coaching stack follows a three-phase technique: large-scale multimodal pre-training on interleaved textual content request knowledge and lengthy contexts; guided refinement with specific debit lessons to strengthen causal and cross-modal reasoning; And reinforcement be taught that verifiable rewards combines with human suggestions to eradicate stem, grounding and agent habits. A easy pondering / non-thinking change states builders who can act the depth of the velocity on demand, in order that the mannequin is tailor-made to different product lecture objectives.
Picture: https://www.globalnewsles.com/uploads/2025/08/8c8146f0727d80970ed4f09b16f316.jpg
Mediacontact
Firm identify: Z.AI
Contact particular person: Zixuan Li
E -Mail: Ship e -Mail [http://www.universalpressrelease.com/?pr=zai-launches-glm45v-opensource-visionlanguage-model-sets-new-bar-for-multimodal-reasoning]
Nation: Singapore
Web site: https://chat.z.ai/
Authorized disclaimer: Data on this web page is supplied by an impartial content material supplier of third events. Getnews gives no ensures or duty or legal responsibility for accuracy, content material, photographs, movies, licenses, completeness, legality or reliability of the knowledge on this article. In case you are affiliated with this text or complaints or copyright points with regard to this text and wish it to be deleted, please contact retract@sscontact.com
This launch is revealed on OpenPR.













$SNORTER IS THE BEST TRADING BOT! EASY WAY TO MAKE MONEY FROM CRYPTO…

Judges Ramp Up Token Freezes As Trump Reduces Federal Enforcement

Identity Verification Market to Reach USD 25.56 Billion by 2030 Driven by Rising Cyber-Fraud and Cloud Adoption




With $1B in open interest XRP and Solana are the new institutional trades
Credit : cryptoslate.com For years, CME’s crypto firm was a narrative with one asset: Bitcoin, supported by his Liquid Futures...


US clears path for companies to hold Bitcoin tax-free
Credit : cryptoslate.com The American Treasury Division and the Inside Income Service have launched interim pointers that significantly facilitate the...


Metaplanet surpasses 30,000 BTC in major acquisition streak
Credit : cryptoslate.com Metaplanet has cemented its place as one of many world’s largest firm holders of Bitcoin and surpassed...


Will Bitcoin be replaced too?
Credit : cryptoslate.com AOL stopped yesterday, September 30, 2025, the entry service, whereas AOL-E-mail and different merchandise proceed to terminate....


Chainlink, Swift and UBS succesfully pilot tokenized fund solution to revolutionize $100 trillion industry
Credit : cryptoslate.com Chainlink has developed a brand new system with SWIFT and UBS with which banks and asset managers...


Will the machine economy fuel the next Ethereum boom?
Credit : cryptoslate.com Ethereum positions its primary layer to coordinate autonomous brokers, a motion that machine locations, to machine commerce...


Will SWIFT’s new crypto ledger choke or boost existing chains?
Credit : cryptoslate.com Swift has announced It provides a blockchain -based ledger to its infrastructure stack. The brand new ledger,...


Fed highlights stablecoins as pivotal to US payment innovation
Credit : cryptoslate.com The American Federal Reserve -Governor Christopher Waller used the SIBOS 2025 part to emphasise the rising curiosity...
-

 Meme Coin7 months ago
Meme Coin7 months agoDOGE Sees Massive User Growth: Active Addresses Up 400%
-

 Blockchain1 year ago
Blockchain1 year agoOrbler Partners with Meta Lion to Accelerate Web3 Growth
-

 Videos1 year ago
Videos1 year agoShocking Truth About TRON! TRX Crypto Review & Price Predictions!
-

 Meme Coin1 year ago
Meme Coin1 year agoCrypto Whale Buys the Dip: Accumulates PEPE and ETH
-

 NFT9 months ago
NFT9 months agoSEND Arcade launches NFT entry pass for Squad Game Season 2, inspired by Squid Game
-

 Solana4 months ago
Solana4 months agoSolana Price to Target $200 Amid Bullish Momentum and Staking ETF News?
-

 Ethereum1 year ago
Ethereum1 year ago5 signs that the crypto bull run is coming this September
-

 Gaming1 year ago
Gaming1 year agoGameFi Trends in 2024
